안녕하세요~! 문쑹입니다 :)
장마철이 다가왔네욤 모두 조심하세요!
인덱스
책의 뒷부분에 있는 색인(또는 찾아보기)와 비슷한 개념이며, 작은 데이터에는 없어도 별 차이가 없지만, 대량의 데이터에는 인덱스가 있어야만 데이터를 빠른 시간에 검색할 수 있다.
인덱스의 장단점
장점
- 검색은 속도가 무척 빨라질 수 있다(물론 반드시 그런 것은 아니다).
- 그 결과 시스템의 부하가 줄어들어서, 결국 시스템 전체의 성능이 향상된다.
단점
- 인덱스가 데이터베이스 공간을 차지해서 추가적인 공간이 필요해 진다(대략 데이터베이스의10% 내외의 공간이 추가로 필요하다).
- 인덱스를 생성하는데 시간이 많이 소요될 수 있다.
- 데이터의 변경 작업(Insert, Update, Delete)이 자주 일어날 경우에는 성능이 많이 나빠질 수도 있다.
인덱스 종류
클러스터형 인덱스 (무리를 '모으다'와 비슷한 개념)
비클러스터형 인덱스 (일반 책의 '찾아보기'와 비슷한 개념)
특징
- 클러스터형 인덱스는 테이블당 1개만 생성
- 비클러스터형 인덱스는 테이블당 여러 개의 생성
- 클러스터형 인덱스는 행 데이터를 인덱스로 지정한 열에 맞춰서 자동 정렬한다.
- 제약조건 없이 테이블 생성시에 인덱스를 만들 수 없다.
- 인덱스가 자동생성되기 위한 열의 제약조건은 Primary Key와 Unique뿐이다.

인덱스 테이블을 실험해보기 위해서 위와 같이 테이블을 만들어주세요
id에 기본키 값을 주고 indexTBL 테이블의 인덱스를 확인해 보면 클러스터형 PK키가 자동 생성된것을 확인할 수 있습니다.
다시 기본 키를 제거 하고 저장한 후 테이블을 새로고침해서 확인을 하였더니 인덱스가 사라졌습니다!
비클러스터형 인덱스를 생성해 보겠습니다.
userTBL 테이블 밑에 인덱스에서 비클러스터형 인덱스를 선택해 주세요!
첫 화면입니다! 저희는 name에 인덱스를 생성해 볼게요
이름도 바꿔주시고 추가 버튼을 눌러줍니다!
name을 선택해주세요 여러 개도 선택 가능합니다.
확인을 눌러서 인덱스를 생성해주세요.
인덱스를 확인하니 잘 적용이 되었네요 :)
인덱스의 내부 작동
B-Tree(Ralanced Tree, 균형 트리)
범용적으로 사용되는 데이터 구조, 인덱스를 표현할 때 많이 사용되며 데이터의 검색(Select)시에 뛰어난 성능을 보일 수 있고 데이터의 변경(Insert, Update, Delete)시에 성능이 나빠질 수 있다.
클러스터형 인덱스의 특징
- 클러스터형 인덱스의 생성시에는 데이터페이지 전체를 다시 정렬하게 된다.
- 클러스터형 인덱스를 생성은 심각한 시스템 부하를 줄 수 있다.
- 클러스터형 인덱스는 인덱스 자체의 리프 페이지가 곧 데이터이다.
- 비 클러스터형 보다 검색속도는 더 빠르다. 하지만, 데이터의 입력/수정/삭제는 더 느리다.
- 클러스터 인덱스는 성능이 좋지만, 테이블에 한 개 밖에 생성하지 못한다. 그러므로, 어느 열에 클러스터형 인덱스를 생성하느냐에 따라서 시스템의 성능이 달라질 수 있다.
비클러스터형 인덱스의 특징
- 비클러스터형 인덱스의 생성시에는 데이터페이지는 그냥 둔 상태에서 별도의 페이지에 인덱스를 구성한다.
- 비클러스터형 인덱스는 인덱스 자체의 리프페이지는 데이터가 아니라, 데이터가 위치하는 포인터(RID)다. 클러스터형보다 검색 속도는 더 느리지만, 데이터의 입력/수정/삭제는 덜 느리다.
- 비클러스터형 인덱스는 여러 개 생성할 수가 있다. 하지만, 함부로 남용할 경우에는 오히려 시스템 성능을 떨어뜨리는 결과를 초래할 수 있으므로, 꼭 필요한 열에만 생성하는 것이 좋다.
인덱스를 생성해야 하는 경우와 그렇지 않은 경우
- 인덱스는 열 단위에 생성된다.
- Where 절에서 사용되는 컬럼을 인덱스로 만든다.
- Where 절에 사용되더라도 자주 사용해야 가치가 있다.
- 데이터의 중복도가 높은 열을 인덱스를 만들어도 별 효용이 없다.
- 외래키가 사용되는 열에는 인덱스를 되도록 생성해 주는 것이 좋다.
- JOIN에 자주 사용되는 열에는 인덱스를 생성해 주는 것이 좋다.
- INSERT/UPDATE/DELETE가 얼마나 자주 일어나는 지를 고려해야 한다.
- 클러스터형 인덱스는 하나만 생성할 수 있다.
- 클러스터형 인덱스가 테이블에 아예 없는 것이 좋은 경우도 있다.
- 사용하지 않는 인덱스는 제거하자.
- 계산열에도 인덱스를 활용할 수 있다.
데이터베이스 트랜잭션 로그 파일과 트랜잭션의 관계
트랜잭션
데이터베이스의 물리적 실체이며 데이터베이스는 물리적으로 파일이다. 기본적으로 '*.mdf'와 '*.ldf' 두 파일이 생긴다.
데이터파일
'*.mdf' 또는 '*.ldf'로 생성된다. 이 파일에는 데이터베이스 개체(테이블, 인덱스 등)와 그 행 데이터가 저장됨
트랜잭션 로그파일
'*.ldf' 로 생성된다. 정전 등의 응급상황에서 입력된 데이터가 완전하도록 하며 전부 되거나 전부 안되거나(All or Nothing) 를 지원함
트랜잭션의 개념
하나의 논리적 작업단위로 수행되는 인련의 작업, SQL문(SELECT/INSERT/UPDATE/DELETE)의 묶음. 한 단위의 트랜잭션은 모두 처리되거나, 모두 처리 되지 않도록 DBMS가 관리해 준다.
자동커밋(Auto Commit)을 방지해주기 위해서 설정하는 방법입니다. 우선 세팅을 해볼게요
상단 메뉴에서 도구-옵션으로 가주세요
왼쪽 창에서 쿼리 실행 - SQL Server - ANSI에서 표시된 부분을 체크 해제 해주세요! 혹시나 체크가 되있다면 COMMIT을 했을 때 ROLLBACK이 적용 안 될 수 있습니다!
그리고 VS2019년버전 부터는 이 작업을 필요성은 없어졌습니다. 하지만 VS2019이전 버전을 사용 중이라면 설정을 해두시는게 좋습니다!
BEGIN TRAN; -- 코드를 실행하기전 먼저 실행!
SELECT * FROM buyTBL
WHERE num = 9;
UPDATE buyTBL
SET price = 100,
amount = 5
WHERE num = 9;
-- COMMIT 과 ROLLBACK을 사용하기 위해서는 BEGIN TRAN을 실행 후 사용 가능! --
COMMIT; -- 데이터 바뀐거 확인 후 데이터 입력을 최종적으로 확인
ROLLBACK; -- 말그대로 이전 값으로 되돌려줌BEGIN TRAN을 꼭! 먼저 실행 해주셔야 합니다. 그리고 작업을 진행 해주셔야지 COMMIT과 ROLLBACK이 적용할 수 있습니다. BEGIN TRAN과 COMMIT,ROLLBACK은 짝꿍입니다! COMMIT을 한 후 데이터가 잘 못 적용된 것을 발견 했을 때는 다시 BEGIN TRAN을 하신 후 ROLLBACK을 해주시면 됩니다. COMMIT한 후 바로 ROLLBACK은 안됩니다! BEGIN TRAN을 한 번더 실행 시켜주셔야합니다. VS2019버전부터 적용되니 이전 버전을 사용 중이신 분들은 위에 자동퍼밋을 설정해주시고 해주세요 :)
트랜잭션의 특성(ACID)
- 원자성(Atomicity) - 트랜잭션은 분리할 수 없는 하나의 단위이다.
- 일관성(Consistency) -트랜잭션에서 사용되는 모든 데이터는 일관되어야 한다.
- 격리성(Isolation) - 현재 트랜잭션이 접근하고 있는 데이터는 다른 트랜잭션에서 격리되어야 한다는 것을 의미한다.
- 영속성(Durability) - 트랜잭션이 정상적으로 종료된다면 그 결과는 시스템 오류가 발생되더라도 시스템에 영구적으로 적용된다.
트랜잭션의 문법과 종류
COMMIT TRAN과 COMMIT WORK는 거의 동일하게 사용되며, ROLLBACK TRAN과 ROLLBACK WORK도 마찬가지다.
구문 형식은 아래와 같다.
BEGIN TRANSACTION(또는 BIGN TRAN)
SQL 문장들
COMMIT TRANSACTION(또는 COMMIT TRAN 또는 COMMIT WORK)
트랜잭션의 종류는 세 가지가 있다.
자동 커밋 트랜잭션
각 쿼리마다 자동적으로 BEGIN TRAN과 COMMIT TRAN이 붙여짐, SQL Server가 디폴트로 사용함
명시적 트랜잭션
직접 BEGIN TRAN과 COMMIT TRAN을 써주는 것
암시적 트랜잭션
오라클 등과 호환을 위해서 사용될 수 있다. BEGIN TRAN은 내부적으로 자동으로 붙여주지만, COMMIT TRAN은 직접 써야한다. SQL Server에서는 암시적 트랜잭션을 별로 권장하지 않지만, 사용하려면 아래와 같이 설정 해줘야한다.
SET IMPLICIT_TRANSACTIONS ON
이전에도 데이터베이스 모델링에 대해 잠깐 다뤘지만 한 번더 다뤄보겠습니다.
데이터베이스 모델링
프로젝트의 진행 단계
프로젝트란 '현실세계의 업무를 컴퓨터 시스템으로 옮겨놓는 일련의 과정' 또는 '대규모의 프로그램을 작성하기 위한 전체 과정'이다. 소프트웨어 분야의 몇몇 개발자에 의존하는 고질적인 문제 때문에 '소프트웨어 개발 방법론'이 대두됨 이러한 분야를 '소프트웨어 공학'이라 부름
폭포수 모델
각 단계가 명확하게 구분되는 장점이 있고 문제점 발생시 앞 단계로 돌아가기는 어렵다. 대규모 프로젝트 일수록, 업무분석과 시스템 설계에 최소 50%이상을 할당하는 것이 좋습니다.
사용자 만들기 설정을 해보겠습니다.
개체 탐색기 - 로그인 - 새 로그인
일반에서 로그인할 아이디 / 비밀번호를 만들어주시고 암호 만료 강제 적용이 체크되어있다면 해제해주세요
사용자 매핑으로 가서 사용할 DB(sqlDB)를 선택해주세요
상태 부분에서 연결 권한과 로그인에 사용에 체크 되어있는 걸 확인한 후 SSMS 끄고 다시 접속해주세요
아까 위에서 설정한 sqlDB가 아닌 다른 DB들은 접속을 할 수 없습니다.
하지만 접속이 가능하게만 해줘서 아무것도 할 수 있는게 없습니다. 그래서 관리자 계정인 sa로 들어가서 권한을 줘보겠습니다.
연결 해제한 후 다시 sa 관리자 계정으로 로그인을 한 후 생성했던 로그인-hanit - 속성으로 들어가줍니다.
사용자 매핑에서 위의 그림과 같이 체크를 해주세요. 그럼 데이터베이스를 보안이 더 강화된 상태로 관리가 가능해집니다.
hanit으로 접속해도 이제 쓰기/읽기 다 가능해집니다!
저장 프로시저(Stored Procedure)
저장 프로시저(Stored Procedure)란 SQL Server에서 제공되는 프로그래밍 기능이다. 저장 프로시저는 한마디로 쿼리문의 집합으로 어떠한 동작을 일괄 처리하기 위한 용도로 사용한다. 간단한 예제를 살펴볼게요.
USE sqlDB;
GO
CREATE PROCEDURE usp_users
AS
SELECT * FROM userTBL; -- 저장 프로시저 내용
GO
EXEC usp_users;기존에는 SELECT * FROM userTBL만 사용했지만, 이제부터는 EXEC usp_users라고 호출만 하면 됩니다.
이제 저희가 저장 프로시저를 만들어 보겠습니다.
개체 탐색기 - sqlDB - 프로그래밍 기능 - 저장 프로시저에서 새로 만들어 주세요.
스크립된 부분을 삭제해도 상관 없습니다!
스크립된 부분을 수정해보겠습니다.
그리고 관리자 계정인 sa로 설정되있어야 합니다. 위에서 사용자 계정인 hanit으로 하니까 데이터를 출력할 수 없었습니다! ㅠㅠ
-- =============================================
-- Author: Kevin
-- Create date: 2020.06.11 15:35
-- Description: userTBL에서 사용자 조회하는 SP
-- =============================================
CREATE PROCEDURE usp_User
AS
BEGIN
SELECT * FROM userTBL;
END
GO코드를 작성해주세요. 하지만 여기서 코드를 잘 못 작성하여 소스를 바꾸고 싶을때는 삭제한 후 다시 만드는 경우가 있습니다. 그럴때는 ALTER을 추가 해주시면 됩니다!
-- =============================================
-- Author: Kevin
-- Create date: 2020.06.11 15:35
-- Description: userTBL에서 사용자 조회하는 SP
-- =============================================
CREATE OR ALTER PROCEDURE usp_User -- 지우거나 수정한다 이미 만들어졌다면 수정을하고 없다면 만든다.
--테이블을 삭제할 필요가 없다.
AS
BEGIN
SELECT * FROM userTBL;
END
GO
만든 저장 프로시저 usp_user가 출력이 되는 것을 볼 수 있습니다.
-- =============================================
-- Author: Kevin
-- Create date: 2020.06.11 15:35
-- Description: userTBL에서 사용자 조회하는 SP
-- =============================================
CREATE OR ALTER PROCEDURE usp_User -- 지우거나 수정한다 이미 만들어졌다면 수정을하고 없다면 만든다.
--테이블을 삭제할 필요가 없다,.
@userID VARCHAR(8) -- 프로시저안에서는 DECLARE를 사용할 필요가 없다
AS
BEGIN
SELECT * FROM userTBL WHERE userID = @userID
END
GO
다시 실행 해보면 에러가 발생한다
@userID를 선언해주었기 때문에 쿼리에서도 인자를 입력해주어야한다.
조금 더 응용해서 써보자면 아래와 같이 사용 가능합니다.
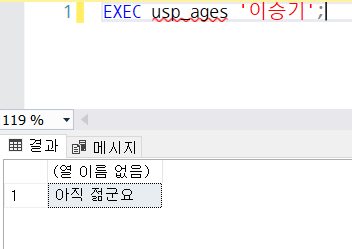
CREATE OR ALTER PROC usp_ages
@userName NVARCHAR(10)
AS BEGIN
DECLARE @mYear INT -- 출생년도 저장 변수
SELECT @mYear = birthYear FROM userTBL
WHERE name = @userName
IF(@mYear >= 1980)
BEGIN
SELECT '아직 젊군요';
END
ELSE
BEGIN
SELECT '다 됐습니다';
END
END
GO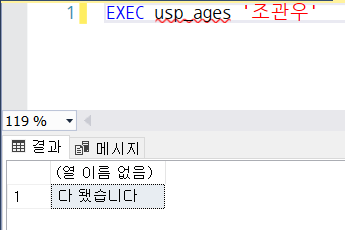
또 다른 예제를 살펴 보겠습니다.
CREATE OR ALTER PROCEDURE usp_Case
@userName NVARCHAR(10)
AS
BEGIN
DECLARE @Year INT
DECLARE @Zodiac NVARCHAR(3)
SELECT @Year = birthYear FROM userTBL
WHERE name = @userName;
SET @Zodiac =
CASE
WHEN (@Year%12 = 0) THEN '원숭이'
WHEN (@Year%12 = 1) THEN '닭'
WHEN (@Year%12 = 2) THEN '개'
WHEN (@Year%12 = 3) THEN '돼지'
WHEN (@Year%12 = 4) THEN '쥐'
WHEN (@Year%12 = 5) THEN '소'
WHEN (@Year%12 = 6) THEN '호랑이'
WHEN (@Year%12 = 7) THEN '토끼'
WHEN (@Year%12 = 8) THEN '용'
WHEN (@Year%12 = 9) THEN '뱀'
WHEN (@Year%12 = 10) THEN '말'
ELSE '양'
END;
PRINT @userName + '는(은) ' + @Zodiac + '띠.';
END
GO
EXEC usp_Case '김문숭';CASE문을 사용하여 호출한 사람의 띠를 알려주는 저장 프로시저입니다.
저장 프로시저의 작동
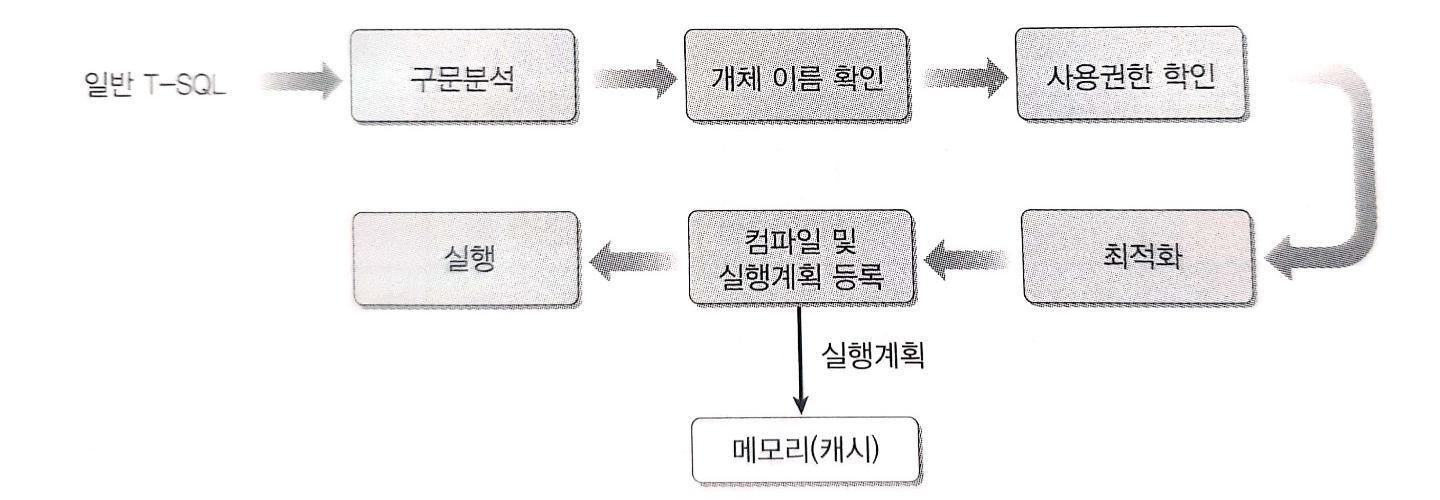
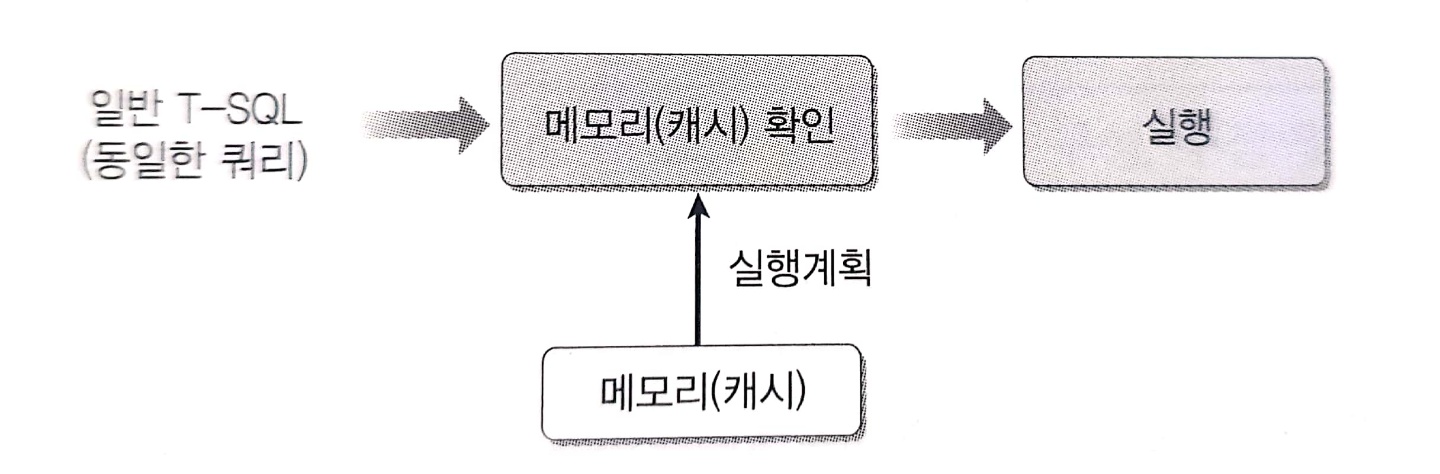
동일한 SQL 문을 실행하면 오른쪽 그림과 같이 간단한 작동을 하게된다. 즉, 시간이 무척 단축된다.
저장 프로시저의 작동 방식
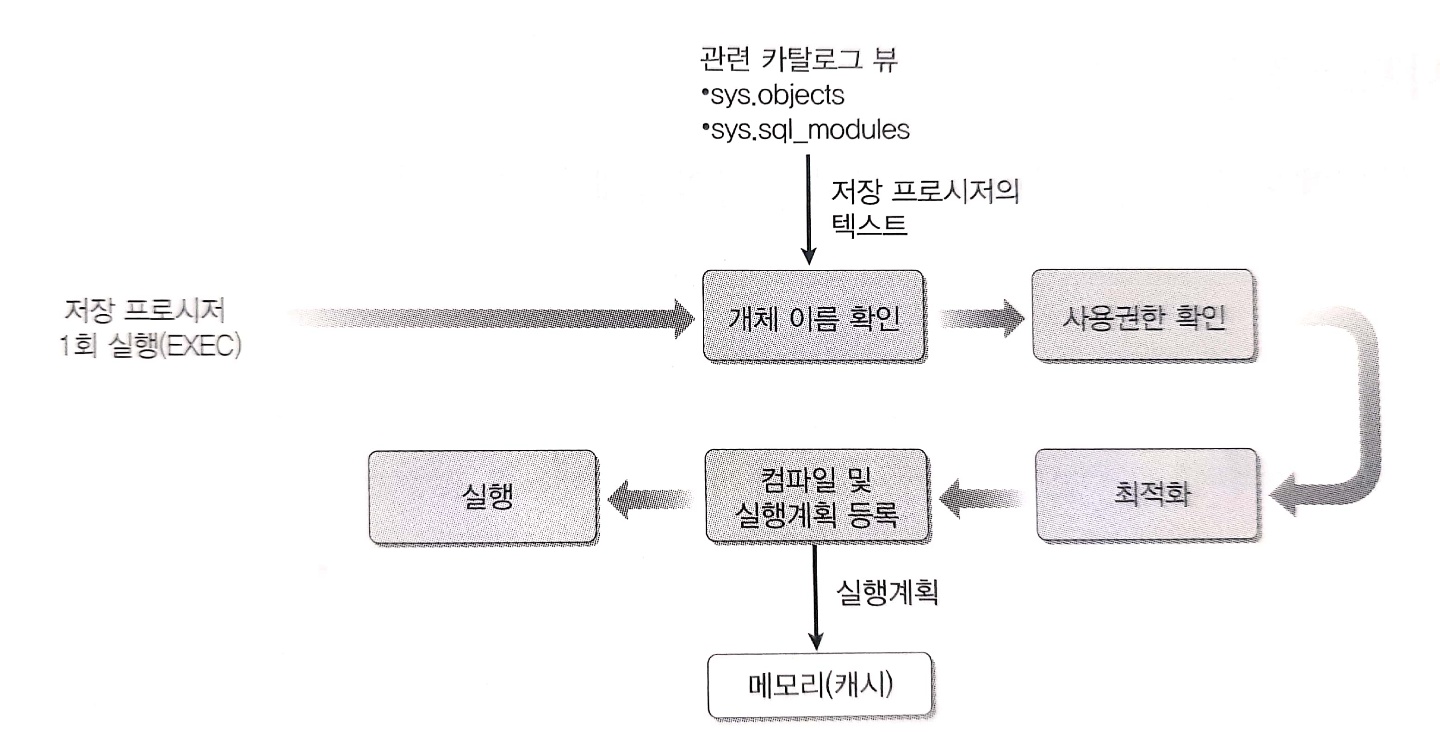
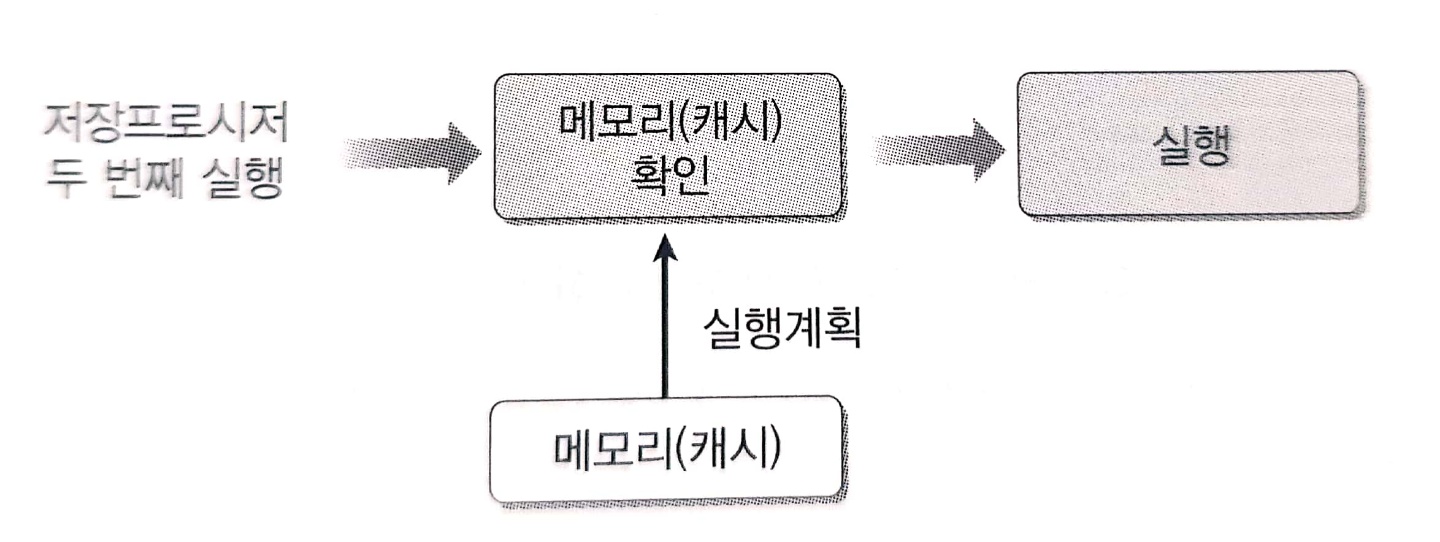
정의 시에 '지연된 이름 확인'을 처음으로 프로시저를 실행하는 순간에 '개체 이름 확인 단계에서 수행하게 된다.
저장 프로시저의 특징
SQL Server의 성능을 향상시킬 수 있다.
- 동일한 저장 프로시저가 자주 사용될 경우에는 일반 쿼리를 반복해서 실행하는 것보다 SQL Server의 성능이 크게 향 상될 수 있다.
모듈식 프로그래밍이 가능하다
- 저장프로시저를 생성해 놓으면, 언제든지 실행이 가능하다.
보안을 강화할 수 있다.
- 사용자 별로 테이블에 접근 권한을 주지 않고, 저장 프로시저에 접근 권한을 줌으로써 좀 더 보안을 강화한다.
네트워크 전송량의 감소시킨다.
- 저장 프로시저 이름 및 매개변수 등 몇 글자의 텍스트만 전송하면 되므로 네트워크 부하를 줄일 수 있다.
저장 프로시저의 종류
사용자 정의 저장 프로시저 (T-SQL, CLR 저장 프로시저)
- T-SQL : 사용자가 직접 CREATE PROCEDURE 문을 이용해서 생성한 프로시저
- CLR : T-SQL 저장 프로시저보다 효율적이고 강력한 프로그래밍 가능
확장 저장 프로시저
- C 언어 등을 이용하여 데이터베이스에서 구현하기 어려운 것들을 구현한 저장 프로시저
시스템 저장 프로시저
- 시스템을 관리하기 위해서 SQL Server가 제공해주는 저장 프로시저
사용자 정의 함수(스칼라 함수)
저장프로시저와 조금 비슷해 보이지만, 일반적인 프로그래밍 언어에서 사용되는 함수와 같이 복잡한 프로그래밍 가능하며 함수는 RETURN문에 의해서 특정 값을 되돌려 준다. 저장프로시저는 'EXEC'에 의해서 실행되지만, 함수는 주로 'SELECT'문에 포함되어 실행됨 (예외도 있음)
사용자의 나이를 출력해보는 소스를 작성해보겠습니다.
FUNCTION을 사용해서 함수를 만들어 줍니다.
만든 함수를 불러올 때는 dbo.를 붙여줘야 하더라구요! 붙여서 출력해줍니다.
사용자 정의 테이블 반환함수
리턴하는 값이 테이블인 함수
인라인 테이블 반환 함수
간단히 테이블을 돌려주는 함수, 매개변수가 있는 뷰와 비슷한 역할을 한다.
CREATE FUNCTION ufn_getUser
(
@height INT
)
RETURNS TABLE
AS
RETURN
(
SELECT userID AS '아이디',
name AS '이름',
height AS '키'
FROM userTBL
WHERE height >= @height
)
GO값에 170, 180을 넣으면 입력한 키 이상인 사람만 출력된다.
다중 문 테이블 반환 함수
다중 문 테이블 반환 함수의 내용에는 BEGIN ... END 로 정의되며, 그 내부에 일련의 T-SQL을 이용해서 반환될 테이블에 행 값을 Insert하는 형식을 가진다.
스키마 바운드 함수
함수에서 참조하는 테이블, 뷰 등이 수정되지 못하도록 설정한 함수
스키마 바운드 함수의 생성은 옵션에 'WITH SCHEMABINDING'을 사용
테이블 변수
일반적인 변수의 선언처럼 테이블 변수도 선언해서 사용
이블 변수의 용도는 주로 임시테이블의 용도와 비슷하게 사용
사용자정의 함수의 제약사항
사용자 정의 함수 내부에 TRY...CATCH문을 사용
이만 포스팅을 마치겠습니다 감사합니다 :)
Hasta Luego~!
